Humans in 4D: Reconstructing and Tracking Humans with Transformers(ICCV’23)
1. 연구 목적 및 기여
1) Problem
- single image에서 3D human mesh를 reconstruction하고, 비디오에서 시간에 따라 추적하는 완전한 트랜스포머 기반 접근법 제시
2. Reconstructing People(HMR 2.0, transformer 기반)
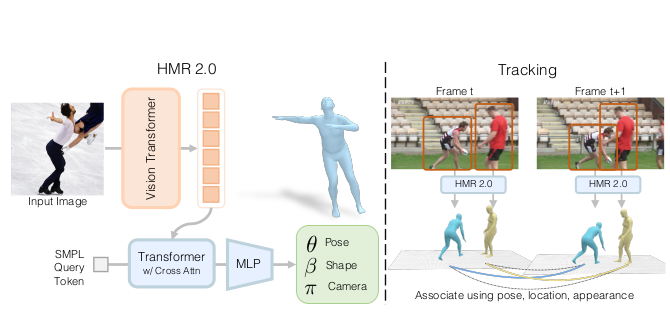
1) Architecture
- Vision Transformer(ViT-H/16) : 이미지를 패치로 분할하여 토큰화
- 트랜스포머 디코더 : SMPL 쿼리 토큰에 cross-attention 수행
- 출력 : SMPL 파라미터 (pose \(\theta\), shape \(\beta\), camera \(\pi\))
2) 특징
- 도메인 특화 설계 없이 end-to-end 학습
- 특이한 자세와 다양한 시점에서도 강건한 성능
- 기존 HMR의 완전한 트랜스포머화
Loss function
- \(\mathcal{L} = \mathcal{L}_{smpl} + \mathcal{L}_{kp3D} + \mathcal{L}_{kp2D} + \mathcal{L}_{adv}\)
- SMPL 파라미터 + 3D/2D keypoint + Adversarial prior
3. Tracking People(4D Humans : 비디오에서의 추적 시스템)
1) 구조
- HMR 2.0으로 각 프레임에서 3D 복원
- 3D 공간에서 추적 수행(Phalp 기반)
- 포즈, 위치, 외형 정보를 활용한 데이터 연관
2) 장점
- 다중 인물 처리 가능
- Occlusion 상황에서도 신원 유지
- Amodal completion으로 누락된 검출 보완
4. Ablation
1) ResNet-50 vs. ViT-H
- ViT-H 대폭적 성능향상
- 사전학습 방식
- Random init : 별로
- MAE사전학습 : 좋음
- MAE + 2D keypoint : best
2) 데이터
- 기본 데이터셋 \(\rightarrow\) +AVA \(\rightarrow\) + 모든 데이터
- 데이터 증가할 때마다 2D 정렬 성능 향상
- 특이한 자세 처리 능력 개선
5. 한계점
1) SMPL 모델 제약
- 손과 얼굴 표정 미포함
- 연령대 다양성 제한 (유아, 어린이)
2) 인물 간 상호작용
- 개별 처리로 인한 세밀한 접촉 표현 어려움
3) 낮은 해상도
- 입력 해상도가 낮을 때 성능 저하
4) 좌표계
- 카메라 프레임 기준 (월드 좌표계 미고려)