WHAM: Reconstructing World-grounded Humans with Accurate 3D Motion(CVPR’24)
0. Video-Based HMR Methods
1) Camera-centric
(카메라를 좌표계 : 카메라를 기준으로 사람의 3D 포즈를 복원, 카메라가 움식이면 사람도 움직임)
- w/o 2D predictions(Image \(\rightarrow\) 3D 직접 예측, End-to-end)
- VIBE(CVPR’20), TCMR(CVPR’21), MAED(CVPR,22), GLoT(ICCV’21), etc..
- 2D-to-3D lifting(Image \(\rightarrow\) 2D keypoints \(\rightarrow\) 3D pose)
- RGB Video → 2D Pose Detector → Lifting Network → 3D pose
- MotionBERT(ICCV’23)
- 장점 : 2D detector는 robust(많은 데이터), 3D GT 없어도 됨
- 단점 : Two-stage라서 느림
2) Global trajectory
(세계 좌표계 : 실제 3D 공간에서의 절대 위치 복원. 카메라가 움직여도 사람은 고정된 위치)
- w/o 2D predictions
- TRACE(CVPR’23)
- 장점 : 빠름
- 단점 : 3D GT 필요
- 2D-to-3D lifting
- ProxyCap, WHAM(CVPR’24)
- 장점 : 2D detector는 robust(많은 데이터), 3D GT 없어도 됨
- 단점 : Two-stage라서 느림
- 3D postprocessing(3D로 예측 \(\rightarrow\) 후처리로 global trajectory 개선
- GLAMR(CVPR’23), SLAHMR(CVPR’24), PACE(3DV’24)
- 장점 : 기존 모델 활용, 특정 문제 집중 해결, Flexible
- 단점 : 초기 예측에 의존, 추가 computation, pipeline 복잡함

1. Problems
1) 기존 방법들의 한계
- 대부분의 방법들이 카메라 좌표계에서만 인간을 추정
- 전역 좌표계 추정 방법들은 평평한 지면을 가정하여 발 미끄러짐 발생
- 가장 정확도가 높은 방법들은 최적화 파이프라인을 사용해 오프라인에서만 동작
- 비디오 기반 방법들이 단일 프레임 방법보다 오히려 부정확함
2) 해결하고자 하는 문제
- 움직이는 카메라로 촬영된 비디오에서 정확하고 효율적인 전역 좌표계 3D human motion reconstruction
- 시간적으로 일관되고 발 미끄러짐이 없는 자연스러운 동작 생성
- 실시간 또는 실시간에 가까운 처리 속도 달성
3) Contributions
- Fuse human motion context and scene context for HMR
- Reduce foot sliding and refine foot contact on non-planar surface
- Effective HMR in global coordinates
- SOTA on in-the-wild benchmarks
2. Methods
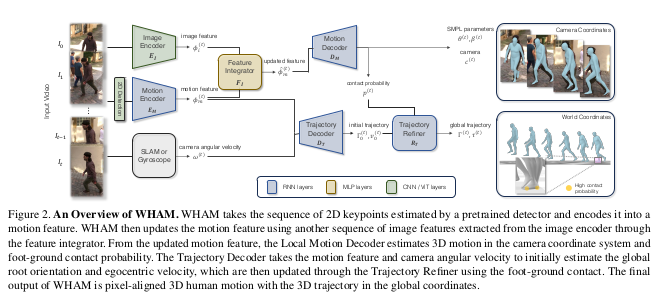
1) Preprocessing Module
- 2D detection
- ViTPose
- Image encoder pretrained with HMR task
- ResNet-50 from SPIN
- HRNet-W48 from CLIFF
- ViT-H/16 from HMR2.0
- These modules are not trained in this work(파인튜닝 하지 않음)
2) Motion Encoder and Decoder
- Unidirectional RNN -> enables online inference
- Motion encoder input
- bbox-normalized 2D keypoints
- Concatenate with box center and scale
- Motion encoder
- Add 3D keypoint regression task using separate linear layer on the motion feaure
- Feature integrator
- Add image feature for shape parameter regression
- Motion decoder
- Outputs : SMPL pose and shape, camera pose, contact probability
3) Global Trajectory Decoder
- Global trajectory devoder
- Regress global root orientation and root velocity
- Append camera angular velocity to the motion feature
- Contact-aware trajectory refinement
- Minimize foot sliding using ground contact probability
- Refine trajectory with additional module
3. Training
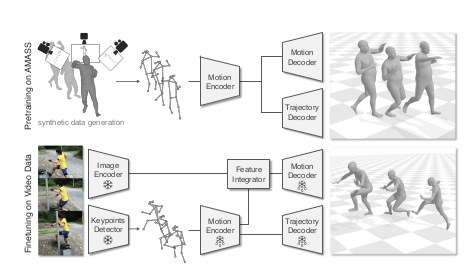
1) Pretraining
- Use AMASS dataset(SMPL mesh only)
- Generate random camera motion
- Obtain 2D keypoints with camera prejection
2) Finetuning
- Studio : Human3.6M, MPI-INF-3DHP
- Outdoor : 3DPW, RICH, EMDB
- No pose GT : InstaVariety
- Synthetic : BEDLAM
- No image : AMASS
4. Results
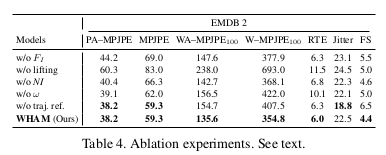
1) Ablation experiments
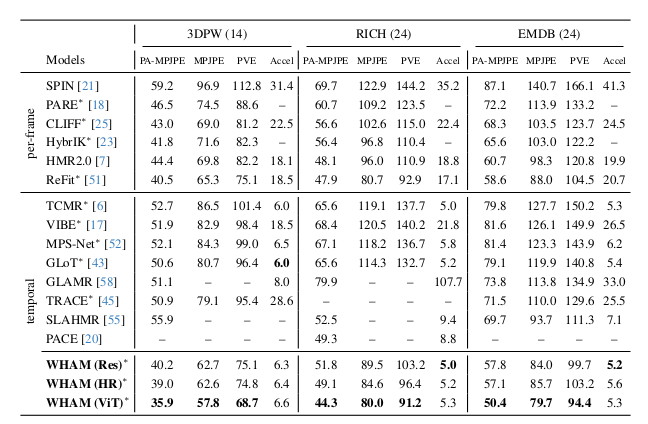
2) Per-frame HMR accracy
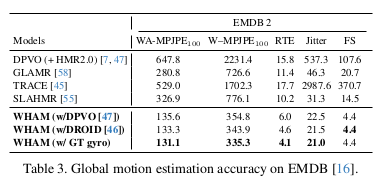
3) Global motion estimation accuracy
4) Failure Cases

- wrong trajectory in case of boarding
- No refinement for hand-ground contact
5. Conclusion and Discussion
1) Conclusion
- 2D-to-3D lifting with image context(= coarse SMPL regression feature)
- Trajectory refinement with foot contact constraints
- Allow non-planar surfaces
- Minimize foot sliding
- Efficient online inference using RNN
2) Discussion
- Contact constraint can be reformulated to cover more general scenarios
- Is it really real-time? (9fps in online inference, 50fps in 64 batch size without SLAM)
- Applicability for long-range trajectory? (> 1 minute)
- Performance on static camera benchmrks? (Human3.6M, MPI-INF-3DHP)