HaMeR : Reconstructing Hands in 3D with Transformers(CVPR’24)
1. Problem
- 단일 RGB 이미지에서 3D Hand mesh reconstructon
- 기존의 한계 : in-the-wild 환경에서 robustness 부족
2. 방법론
1) model architecture
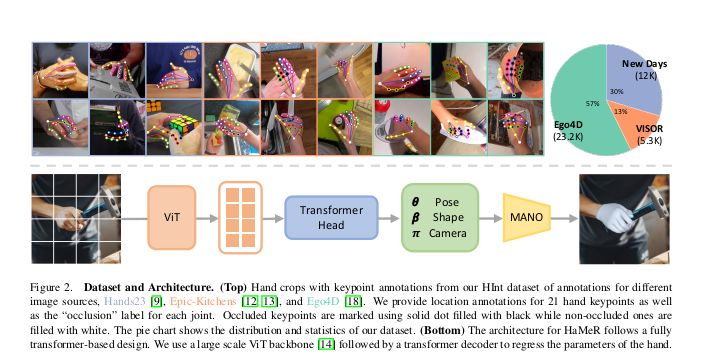
- 완전 transformer 기반
- ViT-H(Vision Transformer-Huse) backvone
- Transformer decoder head
- MANO 파라미터(pose : \(\theta\), shape : \(\beta\), camera : \(\pi\))
2) 학습데이터 (2.7M examples - 기존의 4배)
3) Loss function
- 3D loss : MANO 파라미터 + 3D 조인트
- 2D loss : 2D reprojection loss + adversarial loss
3. 결과
1) 3D
- FreiHAND, HO3D에서 SOTA달성
2) 2D(HInt 벤치마크)
- PCK@0.05에서 2~3배 개선(정확한 keypoints 수 / 전체 keypoints 수)
- ex) New Days 에서 FrankMocap 16.1% \(\rightarrow\) HaMeR 48.1%
3) Ablation study
- large data + large model을 사용했을 때 가장 성능이 좋음
4) 장점
- 다양한 viewpoint 처리
- Occlusion에 강함
- 다양한 피부색, 장갑, 그림 등 일반화
- Single-frame 방법이지만 비디오에서 temporally stable