HMR: End-to-end Recovery of Human Shape and Pose(CVPR’18)
용어 정리
- Mesh Reconstruction : Shape + Pose Reconstruction
- Mesh file : .obj \(\rightarrow\) vertex(꼭짓점 6000 \(\times\) 3), face(면 15000 \(\times\) 3)(integer형태, vertex의 index, face는 고정하고 vertex만 바뀜)
0. abstract
- single RGB image로 3D mesh reconstruction
- 이미지들에 대한 2D keypoint annotation밖에 없을 때 reprojection loss를 최소화하는 것이 목표
- reprojection loss 만으로 학습하는 것은 제약이 부족해, SMPL 파라미터가 real 3D human mesh database로부터 온것인지, network로부터 출력된 값인지 분별하는 discriminator를 추가해서 adversarial training
1. Introduction
1) 기존 방식들의 문제
- 기존 방법들은 3D joint location만 추정
- Joint 만으로는 full DoF를 표현 못함
- \(\rightarrow\) full 3D mesh복원을 목표로 함
2) 어려움
- 3D ground truth 데이터가 거의 없음
- depth ambiguity : 같은 2D projection에 여러 3D구조가 대응가능
- scale ambiguity : 사람 크기와 카메라 거리 간 모호성 존재
3) Overview of the proposed framework
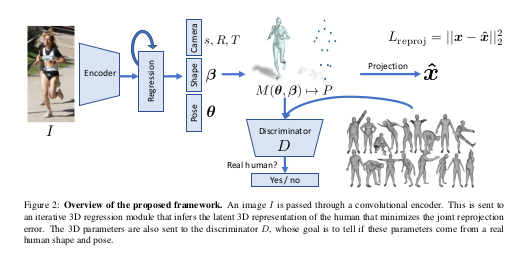
- 이미지가 CNN(ResNet-50)을 통해 인코딩, 이미지 특징 추출.
- 인코딩된 feature vector는 반복적 3차원 회귀 모듈을 통해 파라미터 추정
- 회귀 모듈에서 나온 3차원 형상을 표현하는 latent vector(\(s, R, T, \beta, \theta\))
- reprojection error를 최소화 시키는 방식으로 추론ehla
- latent vector로 3차원 Mesh를 만들고 projection하여 3차원 keypoints를, 한번 더 미분하여 2d keypoints를 얻음. 이것과 본래의 이미지의 2d keypoints의 오차를 최소화 시키도록 학습
- 3차원 mesh를 Discriminator로 전달. pose나 shape이 사람이 아닐 수 있기 때문에 사람인지 아닌지 판별하는 Discriminator 학습
2) 기존과의 차이점
- 이미지 feature에서 바로 3D mesh 파라미터를 추론할 수 있다. (기존 방식은 2D keypoints검출 후 smpl 파라미터를 추론하는 방식) 따라서 2단계로 학습할 필요가 없다.
- 뼈대 뿐만이 아니라 mesh를 출력으로 한다.
- end-to-end로 학습한다.
- 2D에 매칭되는 3D데이터 없이도 좋은 결과를 낸다.
2. Model
1) The set of parameters
- \({\theta, \beta, R, T, s}\) : 85차원 벡터
- \(\theta\) : shape -10dim
- \(\beta\) : pose - 69dim
- \(R\) : rotation - 3dim
- \(t\) : translation -2dim
- \(s\) : scale - 1dim
- \(\hat{\mathbf{x}} = s\mathbf{II}(RX(\theta,\beta)) + t\), \(\mathbf{II}\) is an 2D projection
loss function
- \(L = \lambda(L_{reproj} + \mathbb{1}L_{3D}) +L_{adv}\)
- \(L_{reproj} = \sum{}{i}||v_i(\mathbf{x}_i - \hat{\mathbf{x}}_i)||_1\) : iterative error feedback 방법 사용
- \(L_{3D} = L_{3D joints} + L_{3D smpl}\) : 3D ground truth 있을 때만 사용