import torch
import torchvision
import matplotlib.pyplot as plt GAN : Generative Adversarial Nets(2014)
1. imports
2. GAN(Goodfellow et al. 2014) intro
A. 생성모형이란?
- 사진속에 들어있는 동물이 개인지 고양이인지 맞출수 있는 기계와 개와 고양이를 그릴수 있는 기계중 어떤것이 더 시각적보에 대한 이해가 깊다고 볼 수 있는가?
- 진정으로 인공지능이 이미지자료를 이해했다면, 이미지를 만들수도 있어야 한다. \(\to\) 이미지를 생성하는 모형을 만들어보자 \(\to\) 성공
- 뭘 분류하려는 목적을 가진게 판별모형이면 뭘 만들려는 목적을 가진게 생성모형이고 생성모형이 더 우수하다.
명언: 만들수 없다면 이해하지 못한 것이다, 리처드 파인만 (천재 물리학자)
3. GAN의 구현
A. Data
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=False)
to_tensor = torchvision.transforms.ToTensor()
X_real = torch.stack([to_tensor(Xi) for Xi, yi in train_dataset if yi==3])plt.imshow(X_real[0].squeeze(),cmap="gray")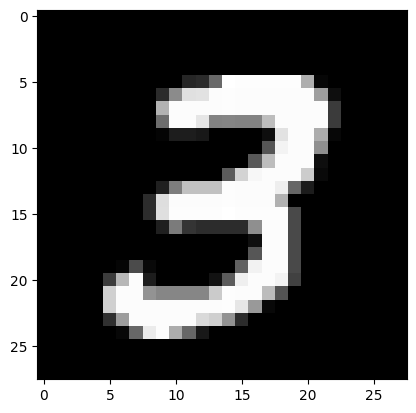
B. 페이커 생성
- net_faker : noise \(\to\) 가짜이미지”를 만들자
- 네트워크의 입력 : (n,??)인 랜덤으로 뽑은 숫자
torch.randn(1,4) # 이게 입력으로 온다고 상상하자. tensor([[ 0.3833, 1.4574, 0.6266, -0.1444]])- 네트워크의 출력: (n,1,28,28)의 텐서
class FlattenToImage(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self,X):
return X.reshape(-1,1,28,28)
net_facker = torch.nn.Sequential(
torch.nn.Linear(4,64),
torch.nn.ReLU(),
torch.nn.Linear(64,64),
torch.nn.ReLU(),
torch.nn.Linear(64,784),
torch.nn.Sigmoid(), # 출력을 0~1로 눌러주기 위한 레이어 // 저한테는 일종의 문화충격
FlattenToImage()
)net_facker(torch.randn(1,4)).shapetorch.Size([1, 1, 28, 28])C. 경찰 생성
- net_police : 진짜 이미지 \(\to\) 0 , 가짜 이미지 \(\to\) 1 과 같은 네트워크 설계
- 네트워크의 입력 : (n,1,28,28) 인 이미지
- 네트워크의 출력 : 0, 1
net_police = torch.nn.Sequential(
torch.nn.Flatten(),
torch.nn.Linear(784,30),
torch.nn.ReLU(),
torch.nn.Linear(30,1),
torch.nn.Sigmoid()
)D. 바보 경찰과 바보 페이커
- 데이터
real_image = X_real[[0]] # 진짜이미지
fake_image = net_facker(torch.randn(1,4)).data # 가짜이미지- 경찰 네트워크가 가짜 이미지와, 진짜 이미지를 봤을 때 각각 어떤 판단을 할까
-진짜 이미지를 봤을 때
net_police(real_image) # -> 0으로 가야함tensor([[0.4829]], grad_fn=<SigmoidBackward0>)- 가짜 이미지를 봤을 떄
net_police(fake_image) # -> 1로 가야함tensor([[0.4764]], grad_fn=<SigmoidBackward0>)- 아직 아쉬운 판단..
E. 똑똑해진 경찰
- 데이터를 정리
- 원래 \(n=6131\)개의 이미지자료가 있었음. 이를 \({\bf X}_{real}\) 로 저장했었음.
- \({\bf X}_{fake}\)는
net_facker의 output으로 생성하고 꼬리표 제거. - \({\bf X}_{real}\)에 대응하는 \({\bf y}_{real}\) 생성. 진짜이미지는 라벨을 0으로 정함.
- \({\bf X}_{faker}\)에 대응하는 \({\bf y}_{fake}\) 생성. 가짜이미지는 라벨을 1로 정함.
X_fake = net_facker(torch.randn(6131,4)).data
y_real = torch.zeros((6131,1))
y_fake = torch.ones((6131,1))- step1: X_real, X_fake를 보고 각각 yhat_real, yhat_fake를 만드는 과정
yhat_real = net_police(X_real)
yhat_fake = net_police(X_fake)- step2: 경찰의 미덕은 (1) 가짜이미지를 가짜라고 하고 (2) 진짜이미지를 진짜라고 해야함.
- 즉 yhat_real 은 거의 0의 값으로, 그리고 yhat_fake는 1이 되도록 설계해야함. (yhat_real \(\approx\) y_real 이고 yhat_fake \(\approx\) y_fake 이어야 함) 이러면 경찰이 잘하는것.
bce = torch.nn.BCELoss()loss_police = bce(yhat_real,y_real) + bce(yhat_fake,y_fake)
loss_policetensor(1.3918, grad_fn=<AddBackward0>)- 합쳐서 계산하는 방법
torch.concat([X_real,X_fake],axis=0).shapetorch.Size([12262, 1, 28, 28])torch.concat([y_real,y_fake],axis=0).shapetorch.Size([12262, 1])bce(net_police(torch.concat([X_real,X_fake],axis=0)),torch.concat([y_real,y_fake],axis=0))*2tensor(1.3918, grad_fn=<MulBackward0>)-step 3~4
# net_police = torch.nn.Sequential(
# torch.nn.Flatten(),
# torch.nn.Linear(784,30),
# torch.nn.ReLU(),
# torch.nn.Linear(30,1),
# torch.nn.Sigmoid()
# )
bce = torch.nn.BCELoss()
optimizr_police = torch.optim.Adam(net_police.parameters())
for epoc in range(30):
X_fake = net_facker(torch.randn(6131,4)).data
# step1 -- yhat을 얻음
yhat_real = net_police(X_real)
yhat_fake = net_police(X_fake)
# step2 -- loss를 계산
loss_police = bce(yhat_real,y_real) + bce(yhat_fake,y_fake)
# step3 -- 미분
loss_police.backward()
# step4 -- update
optimizr_police.step()
optimizr_police.zero_grad()- 경찰의 실력향상 감상
net_police(X_real) # 거의 0으로 tensor([[0.0099],
[0.0126],
[0.0132],
...,
[0.0165],
[0.1010],
[0.0247]], grad_fn=<SigmoidBackward0>)net_police(net_facker(torch.randn(6131,4)).data) # 거의 1로tensor([[0.9775],
[0.9775],
[0.9773],
...,
[0.9773],
[0.9773],
[0.9775]], grad_fn=<SigmoidBackward0>)- 꽤 우수한 경찰..
fig, ax = plt.subplots(1,2)
ax[0].imshow(X_fake[[2]].squeeze(),cmap="gray")
ax[0].set_title(f"police output = {net_police(X_fake[[2]]).item():.4f}")
ax[1].imshow(X_real[[-1]].squeeze(),cmap="gray")
ax[1].set_title(f"police output = {net_police(X_real[[-1]]).item():.4f}")Text(0.5, 1.0, 'police output = 0.0247')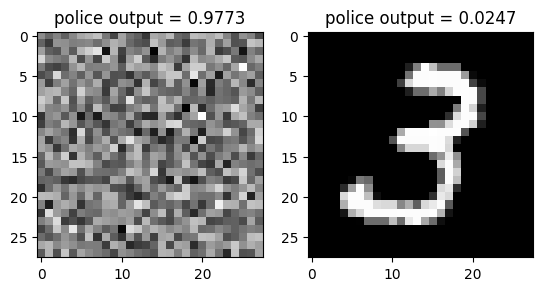
F. 더 똑똑해지는 페이커
- step1 : noise \(\to\) X_fake
X_fake = net_facker(torch.randn(6131,4))
# 여기서는 X_fake가 데이터가 아니고 네트워크 출력이므로 꼬리표를 제거하지 말아야함- step2: 손실함수 - 페이커의 미덕 (잘 훈련된) 경찰이 가짜이미지를 진짜라고 판단하는 것. 즉 yhat_fake \(\approx\) y_real 이어야 페이커의 실력이 우수하다고 볼 수 있음.
yhat_fake = net_police(X_fake)
loss_faker = bce(yhat_fake, y_real)
# 가짜이미지를 보고 잘 훈련된 경찰도
# 진짜 이미지라고 깜빡 속으면
# 위조범의 실력이 좋다고 볼 수 있다는 의미class FlattenToImage(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self,X):
return X.reshape(-1,1,28,28)
net_facker = torch.nn.Sequential(
torch.nn.Linear(4,64),
torch.nn.ReLU(),
torch.nn.Linear(64,64),
torch.nn.ReLU(),
torch.nn.Linear(64,784),
torch.nn.Sigmoid(), # 출력을 0~1로 눌러주기 위한 레이어 // 저한테는 일종의 문화충격
FlattenToImage()
)
bce = torch.nn.BCELoss()
optimizr_facker = torch.optim.Adam(net_facker.parameters())for epoc in range(1):
# step1 -- yhat을 얻음
X_fake = net_facker(torch.randn(6131,4))
# step2 -- loss를 계산
yhat_fake = net_police(X_fake)
loss_faker = bce(yhat_fake,y_real)
# step3 -- 미분
loss_faker.backward()
# step4 -- update
optimizr_facker.step()
optimizr_facker.zero_grad()- 위조범의 실력향상 감상
plt.imshow(X_fake[[0]].squeeze().data,cmap="gray")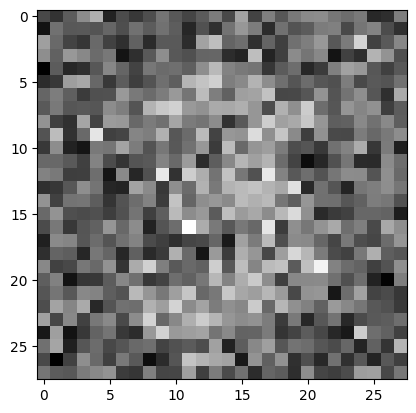
G. 경쟁학습 (최종코드)
torch.manual_seed(43052)
net_police = torch.nn.Sequential(
torch.nn.Flatten(),
torch.nn.Linear(784,30),
torch.nn.ReLU(),
torch.nn.Linear(30,1),
torch.nn.Sigmoid()
)
class FlattenToImage(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self,X):
return X.reshape(-1,1,28,28)
net_facker = torch.nn.Sequential(
torch.nn.Linear(4,64),
torch.nn.ReLU(),
torch.nn.Linear(64,64),
torch.nn.ReLU(),
torch.nn.Linear(64,784),
torch.nn.Sigmoid(), # 출력을 0~1로 눌러주기 위한 레이어 // 저한테는 일종의 문화충격
FlattenToImage()
)
bce = torch.nn.BCELoss()
optimizr_police = torch.optim.Adam(net_police.parameters(),lr=0.001, betas=(0.5,0.999))
optimizr_facker = torch.optim.Adam(net_facker.parameters(),lr=0.0002, betas=(0.5,0.999))for epoc in range(1000):
#--- net_police 를 훈련
#step1
X_fake = net_facker(torch.randn(6131,4)).data # 여기에서 X_fake는 data를 의미
yhat_real = net_police(X_real)
yhat_fake = net_police(X_fake)
#step2
loss_police = bce(yhat_real,y_real) + bce(yhat_fake,y_fake)
#step3
loss_police.backward()
#step4
optimizr_police.step()
optimizr_police.zero_grad()
#--- net_faker 를 훈련
#step1
X_fake = net_facker(torch.randn(6131,4)) # 이때 X_fake는 net의 out을 의미
#step2
yhat_fake = net_police(X_fake)
loss_facker = bce(yhat_fake, y_real)
#step3
loss_facker.backward()
#step4
optimizr_facker.step()
optimizr_facker.zero_grad()fig, ax = plt.subplots(2,5,figsize=(10,4))
k=0
for i in range(2):
for j in range(5):
ax[i][j].imshow(X_fake[[k]].data.squeeze(),cmap="gray")
ax[i][j].set_title(f"police out = {net_police(X_fake[[k]]).item():.4f}")
k= k+1
fig.tight_layout()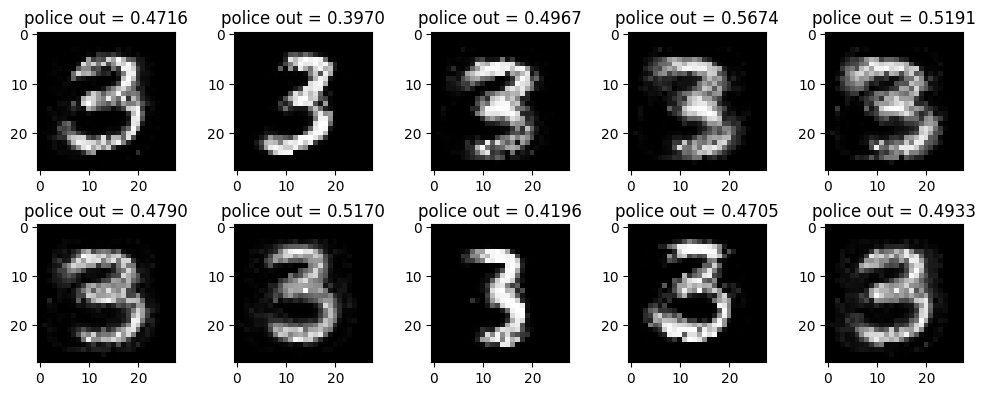
5. 초기 GAN의 한계점
- 두 네트워크의 균형이 매우 중요함 – 균형이 깨지는 순간 학습은 실패함
- 생성되는 이미지의 다양성이 부족한 경우가 발생함. (mode collapse)
Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. “Generative Adversarial Nets.” Advances in Neural Information Processing Systems 27.
- 적당히 비슷해야함
- 경찰이 너무 똑똑하면 (판별을 잘하면)..학습을 다 못해버림
- 아니면 속이는 다 똑같은 이미지 생성